Obsah
Poslední změna: pondělí 9. března 2009
Při zapnutí počítače je potřeba zvolit bootování ze sítě. Po naběhnutí OS se přihlaste svým uživatelským jménem a heslem jako obvykle.
Shell, neboli příkazová řádka, je základním prostředkem pro komunikaci uživatele a počítače. Linuxový shell má oproti tomu, co bylo v DOSu nebo je nyní ve Windows, mnoho výhod. Je to v podstatě kompletní programovací jazyk.
Po spuštění se shell ohlásí tzv. promptem.
[sojkam1@stud1-186 src]$
Co je zobrazeno v promptu je volitelné a v příkladu výše je
uvedeno jméno uživatele (sojkam1), jméno počítače (stud1-186) a název
aktuálního adresáře (src). Poslední znak
$ oznamuje, že se jedná o normálního
uživatele. Pokud by tam byl znak #, je
to upozornění, že jste přihlášen jako tzv. superuživatel (root). Viz
sekce 2.3 – „Uživatelé“ a 2.4 – „Souborový systém“.
Za promptem může uživatel psát příkazy. Příkaz je název spustitelného souboru. Například příkazem ls se vypíše obsah aktuálního adresáře:
[sojkam1@stud1-186 src]$ ls linux linux-2.4 linux-2.4.25 redhat
Příkazům lze předávat různé
parametry. Jméno příkazu a jednotlivé parametry
se oddělují mezerou. Speciálním typem parametru
jsou tzv. přepínače, což jsou (většinou) buď
jednopísmenné řetězce začínající znakem
- nebo delší slova začínající
--.
[sojkam1@stud1-186 src]$ ls -l --reverse linux-2.4.25 total 3848 -rwxr-xr-x 1 root root 3098440 Feb 25 09:55 vmlinux -rw-r--r-- 1 root root 563823 Feb 25 09:55 System.map
V
tomto příkladu byl spuštěn příkaz ls s přepínači
-l a --reverse a
parametrem linux-2.4.25.
Přepínače mohou a nemusí mít parametr. Například přepínač
-l nemá žádný parametr, ale jak uvidíme dále,
překladači jazyka C obvykle předáváme přepínač
-o s parametrem, který udává jméno výsledného
souboru (-o soubor).
Většina často používaných Unixových příkazů je velmi krátká. Jejich názvy mají dva nebo tři znaky a tak není problém je psát velmi rychle. Občas se ale setkáme s dlouhými názvy příkazů nebo potřebujeme napsat na příkazovou řádku dlouhé jméno souboru. Tabulátorové doplňování vám velmi usnadní život. Začněte psát začátek příkazu nebo jména souboru a stiskněte klávesu Tab. Pokud to, co jste doposud napsali je jedinečné, automaticky se doplní zbytek názvu. V opačném případě se ozve pípnutí a po dalším stisku Tab se objeví seznam všech příkazů nebo jmen souborů, které začínají napsanou sekvencí znaků.
V unixových systémech bývá zvykem, že ke všemu existuje dokumentace. Základním typem dokumentace jsou tzv. manuálové stránky. Pro zobrazování manuálových stránek slouží příkaz man[1]. Jako parametr se uvádí jméno příkazu, jméno konfiguračního souboru nebo jméno funkce.
man man man ls man strlen
Manuálové stránky jsou děleny do osmi kapitol (sections).
Například v kapitole 1 jsou všechny příkazy, v kapitole 2 systémová
volání a v kapitole 3 knihovní funkce (více viz např. tato stránka). Pokud zadáme
např. man printf, zobrazí se stránka příkazu printf
a ne to co pravděpodobně chceme víc – stránka funkce
printf. To se dá napravit uvedením čísla
kapitoly. Např. man 3 printf.
Manuálové stránky obsahují většinou jen stručný přehled základních informací a jsou určeny spíš pro uživatelé, kteří jsou s příkazem/funkcí již seznámeni. Naproti tomu info stránky (někdy se jim říká TeXinfo dokumentace) obsahují většinou mnohem více informací, jsou hypertextové a jsou koncipovány jako kniha. Základním příkazem pro zobrazení info stánek je příkaz info, ale jeho ovládání není příliš intuitivní. Lepší je používat program pinfo.
[sojkam1@stud1-186 src]$ pinfo gcc
Po jednotlivých odkazech ve stránkách se člověk pohybuje pomocí kurzorových kláves.
Z grafických programů lze info (i man) stránky prohlížet například v konqueroru. Do řádky s adresou stačí napsat info:gcc.
Unixové systémy důsledně používají koncept uživatelů. Základní myšlenka je ta, že existuje jeden správce systému (root) a obyčejní uživatelé. Root může všechno, kdežto uživatelé mohou dělat jen to, jim root povolí. Většinou mají povoleny všechny činnosti, kterými neohrožují jiné uživatele.
Každý uživatel má tedy jistá práva. Například právo zapisovat do určitých souborů a adresářů. Pokud uživatel spustí nějaký program, tento program má stejná práva jako uživatel, který program spustil.
Každý uživatel je členem alespoň jedné skupiny. Práva lze přidělovat i skupinám a uživatel má pak i práva všech skupin kterých je členem.
Souborový systém v Unixu se liší od souborového systému OS Windows zejména v těchto věcech:
Rozlišují se velká a malá písmena.
Adresáře se oddělují normálním lomítkem (/) a ne zpětným (\).
Všechny disky jsou mountovány (připojovány) do jedné adresářové struktury. Neexistují tedy různé disky jako např.
C:. Například CD mechanika je přístupná pod/media/cdrom[2]Každý soubor a adresář má svého majitele a skupinu které patří. Rovněž má práva, která udávají co kdo smí se souborem dělat. Jedno z práv je i právo na spouštění programu.
Spustitelné soubory mohou mít libovolnou příponu, ale většinou se používá jméno bez přípony. Že je soubor spustitelný se pozná podle práv.
Existují tzv. symbolické odkazy.
Pro práci se soubory slouží různé příkazy. Mezi nejpoužívanější patří ls, cd, cp, mv, mkdir apod. Pro pohodlnější práci lze využít souborový manager Midnight commander mc.
Při vývoji programu v jazyce C se postupuje v několika fázích. Nejdříve se napíší zdrojové texty. Ty se pak přeloží překladačem a výsledkem je tzv. objektový soubor. Máme-li více zdrojových textů, získáme i více objektových souborů. Pro vytvoření spustitelného programu je potřeba objektové soubory slinkovat (spojit) linkerem.
V této sekci se stručně seznámíme s jednotlivými částmi popsaného vývojového řetězce. Základní filozofie Unixu říká, že na program má dělat jednu věc a má jí dělat pořádně. Vzájemnou interakcí různých programů se pak dosahuje požadovaných výsledků. Proto nejprve představíme jednotlivé nástroje a pak si povíme o tom jak jejich činnost spojovat.
Leckdy, zejména při vývoji grafických aplikací, je užitečné mít všechny nástroje integrované do jednoho prostředí, tzv. IDE. Hojně používané IDE pro Linux se jmenuje kdevelop, či Eclipse.
Zkušení uživatelé Unixu používají většinou editory Emacs nebo vim. Oba editory jsou velmi silné nástroje, ale naučit se je efektivně ovládat není vůbec jednoduché. Začátečníci spíš sáhnou po editorech, které nenabízí tolik možností, ale jejich ovládání je jednodušší. Takovými editory jsou např. joe nebo mcedit (součást Midnight Commanderu). Z grafických editorů jmenujme například kate.
Zkusíme napsat jednoduchý program hello.c, na
kterém si v následujících sekcích vysvětlíme jak pracovat s
překladačem.
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("Hello world!\n");
return 0;
}
Nejjednodušší způsob jak přeložit výše uvedený program je spustit příkaz
[sojkam1@stud1-191 hello]$ gcc -o hello hello.c
Tím
spustíme překladač, kterému říkáme, že má přeložit soubor
hello.c a výsledek má uložit do souboru
hello. Překladači můžeme předávat spoustu
parametrů. Ze všech bych zmínil aspoň přepínač
-g, který zapne generování ladicích informací a
výsledný soubor lze pak snadno ladit a přepínač
-Wall, který zapne vypisování všech možných
varování při překladu.
Na obrázku 1 – „Fáze překladu zdrojového kódu v jazyce C“ je znázorněno schéma překladu zdrojového souboru v jazyku C.
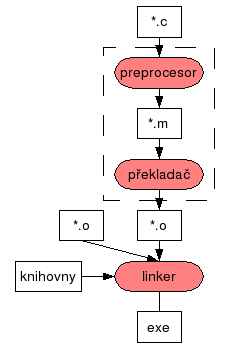
V situaci, kdy máme jeden zdrojový soubor není problém spouštět překladač pokaždé ručně. U větších projektů ale máme souborů víc a často různých typů – máme třeba zdrojové kódy v C a v assembleru, dokumentaci v XML a třeba i něco dalšího. Překládat ručně každý soubor zvlášť a ještě k tomu jiným překladačem a spojovat výsledek dohromady je zbytečně velká práce. Proto byl vymyšlen program make. Jeho základní myšlenka je ta, že se popíše jak se překládá který typ souboru a stanoví se které soubory jsou potřeba pro "vyrobení" jiného souboru.
Program make funguje tak, že po spuštění si
přečte soubor Makefile, kde jsou zapsána pravidla
pro kompilaci a vyvolává postupně překladače tak, jak je potřeba.
V souboru makefile existují čtyři typy řádek:
popis závislostí,
příkazy pro kompilaci,
nastavování proměnných,
komentáře.
Nejjednodušší Makefile pro kompilaci programu
hello vypadá následovně.
hello: hello.c
Obsahuje pouze jednu řádku s popisem závislostí. Takto zapsaná
řádka říká, že pro vytvoření souboru hello je
potřeba soubor hello.c. Tomu, co je vlevo od
dvojtečky se říká target (cíl) a vše co je napravo
jsou takzvané prerekvizity.
Program make má v sobě vestavěna
implicitní pravidla, díky nimž ví, jak má provést
překlad. Kdyby tato pravidla neexistovala, musel by náš
Makefile vypadat takto:
hello: hello.c gcc -Wall -o hello hello.c
Na druhé řádce, která začíná tabulátorem, je
příkaz, který bude vykonán pokud make usoudí, že je
potřeba překompilovat soubor hello.
Implicitní pravidla říkají, jak z jednoho typu souboru vyrobit jiný typ souboru. Tato pravidla jsou většinou definována pomocí proměnných. Chceme-li implicitní pravidlo jen trochu pozměnit, nemusíme ho definovat znova, ale stačí změnit jen hodnoty proměnných, které se v pravidlech používají.
CFLAGS = -g -Wall CC = m68k-elf-gcc hello: hello.c
Pomocí proměnné CFLAGS se například určuje, s
jakými přepínači má být spouštěn překladač jazyka C. Jak se jmenuje
překladač se zase specifikuje v proměnné CC[3].
Pokud chceme překládat větší projekt, bývá zvykem rozšířit
Makefile o další targety:
all: hello clean: rm -f hello hello: hello.c gcc -Wall -g -o hello hello.c
O programu make by toho šlo napsat mnohem víc.
Jdou pomocí něj překládat i velmi komplikované projekty jako například
samotné jádro Linuxu. Dost často ale není potřeba vytvářet složité
soubory Makefile ručně. Nástroje jako
autoconf či nějaké IDE
většinou Makefile generují automaticky.
Při hledání chyby v programu je užitečné mít možnost program ladit.
Máte-li program přeložen s ladicími informacemi (přepínač
-g), zkuste spustit debugger příkazem ddd
hello.
Linux Dokumentační projekt – rozsáhlá kniha zabývající se mnoha aspekty GNU/Linuxu. Pro základní seznámení s Linuxem stačí nahlédnout do části 1, kapitol 1 až 7.
Programování pod Linuxem pro všechny – seriál na root.cz
Advanced Linux Programming – kniha o programování v Linuxu (anglicky, PDF)
Co našel Google
Pavel Herout, Učebnice jazyka C – velmi podařená učebnice
Stručný přehled základní syntaxe jazyka C – učební text předmětu PJR
Dokumentace k programu make: oficiální manuál a tutorial s pěknými obrázky.
Všechny připomínky k předmětu, obsahu stránek, objevené chyby v ukázkových programech apod. adresujte na autory: